



If the only tool you have is a hammer, you tend to see every problem as a nail.
- Abraham Maslow
My 2004 Game Developers Conference lecture was titled Lemke's Algorithm: The Hammer in Your Math Toolbox. It was a pretty hard-core math lecture that turned out to be grossly mistitled in retrospect. I should have called it The Mixed Linear Complementarity Problem: The Hammer in Your Math Toolbox, because not only did I not talk about Lemke's Algorithm at all in the lecture, but also because Lemke's Algorithm is only one way to solve the real topic of the talk, the Mixed LCP, or MLCP.
The problems are defined formally as follows:
| LCP | MLCP | |
|---|---|---|
|
|
|
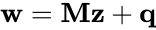
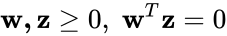
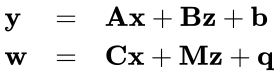
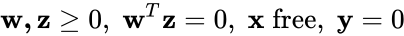
LCPs and MLCPs look pretty simple, but the complementarity conditions (w is 0 when z is not, and vice versa) and non-negativity conditions (w and z are ≥ 0) make them subtle and powerful.
The main thrust of the talk is that you can transform a lot of disparate problems into MLCPs, and then solve them all with a single solver. The nail is the MLCP, and the hammer is Lemke's Algorithm. Maybe there is a more optimal specific solver for one of the original problems, but the value in the hammer-nail dichotomy is that you've already got the hammer sitting there, so being able to transform problems into nails becomes valuable even if it's not the optimal solution. You can always optimize it later.
It's also a romp through a bunch of interesting math, including:
- A derivation of simple ease curve cubic splines, so you can see how to make your own given any 4 constraints on the endpoints and derivatives you want. I derive new cubics like this all the time, and it's a super useful technique to internalize.
- A somewhat-understandable discussion of the Karush-Kuhn-Tucker (KKT) optimality conditions, which are fundamental to understanding numerical optimization.
I don't think the lecture is that great. The ideas are good, the math is amazing and useful, but the exposition and examples are not perfect. As I was doing this talk, I was beginning to question my approach to giving technical lectures, and wondering about how to do it better...something I'm still struggling with and will write about at some point.
The materials...
- The slides.
- The mp3.
- My Objective Caml implementation of Lemke's Algorithm.
This implementation supports MLCPs and an "advanced start", which makes it the most advanced free Lemke's Algorithm source code I know about. It's also super inefficient and dumb, which maybe makes it slightly less advanced, but hey, it's still free. :) It depends on my amazingly lame linear algebra library, Linalg. - Here is an old pdf I sent out to usenet and some professors when I was learning this stuff. Todd Munson replied and set me straight and taught me about the rarely documented "advanced start", which is what makes MLCP solvers actually work. This doc is mostly useful because it shows explicitly working through a tableau, although most books on linear programming and operations research do the same.
The Future?
It turns out, I've since found that there's an even better nail that is a superset of the MLCP, and it's called Second Order Cone Programming, but I haven't done much more than read some papers about it. I recommend starting with these slides; this is a truly awesome presentation from Stephen Boyd at Standford. It's awesome to me because it was the first time I came across a clear statement of the emerging message of modern numerical analysis and optimization, namely that the classical view that linear problems are easy and nonlinear problems are hard is not accurate. Instead:
...the great watershed in optimization isn't between linearity and nonlinearity, but convexity and nonconvexity.
- R. Rockafellar
It looks like there are super fast Interior Point methods that will solve all kinds of crazy nonlinear but convex problems in basically the same amount of time as it takes to solve an equivalently sized Linear Program, which is to say, really fast. I need more experience with this stuff to know for sure, but it seems totally cool.